Большие данные начали активно расти десятилетие назад и не показывают признаков замедления. Этот процесс связан главным образом с интернетом, включая социальные сети, поисковые запросы, текстовые сообщения и медиа-файлы. Другая гигантская доля данных производится устройствами интернета вещей (IoT устройствами) и датчиками. Они и есть те самые ключевые факторы для глобального роста рынка данных, который уже достиг в размере 49 миллиардов долларов по данным Statista. Все в мире сейчас опирается на информацию, и это подталкивает компании искать экспертов в больших данных, способных быстро собирать данные и применять сложную обработку. Но будет ли так продолжаться, какое будет будущее больших данных? В этой статье мы приведем мнения экспертов и пять прогнозов о будущем больших данных.
1. Большие данные продолжат увеличиваться в объемах и будут мигрировать в облако
Большинство экспертов сходятся в том, что объем генерируемых данных в будущем будет расти в геометрической прогрессии. IDC в своем отчете Data Age 2025 для компании Seagate прогнозирует, что глобальная база данных достигнет 175 зеттабайт к 2025 году. К примеру, в 2013 году глобальных данных было произведено 4.4 зеттабайта.
Что убеждает экспертов в таком быстром росте? Во-первых, растущее число интернет-пользователей, делающих все онлайн, пользователи работают в интернете, ведут деловую переписку, совершают покупки и пользуются социальными сетями.

Во-вторых, миллиарды подключенных устройств и встраиваемых систем, которые создают и собирают данные каждый день по всему миру.
Когда компании получат возможность хранить и анализировать огромные объемы данных, они смогут создавать и управлять 60% больших данных в мире в ближайшем будущем. Тем не менее, пользователи интернета также играют важную. В том же отчете IDC отмечают, что 6 миллиардов пользователей или 75% населения мира будут взаимодействовать с онлайн-данными каждый день к 2025 году. Иначе говоря, каждый подключенный пользователь будет взаимодействовать с данными каждые 18 секунд.
С такими большими наборами данных сложно работать с точки зрения их хранения и обработки. До недавнего времени сложные задачи по обработке больших данных решались с помощью экосистем с открытым исходным кодом, таких как Hadoop и NoSQL. Однако технологии с открытым исходным кодом требуют ручной настройки и устранения неполадок, что в свою очередь может быть затруднительным для большинства компаний. Решением стали облачные хранилища – компании начали переносить данные в облако, чтобы быть более гибкими.
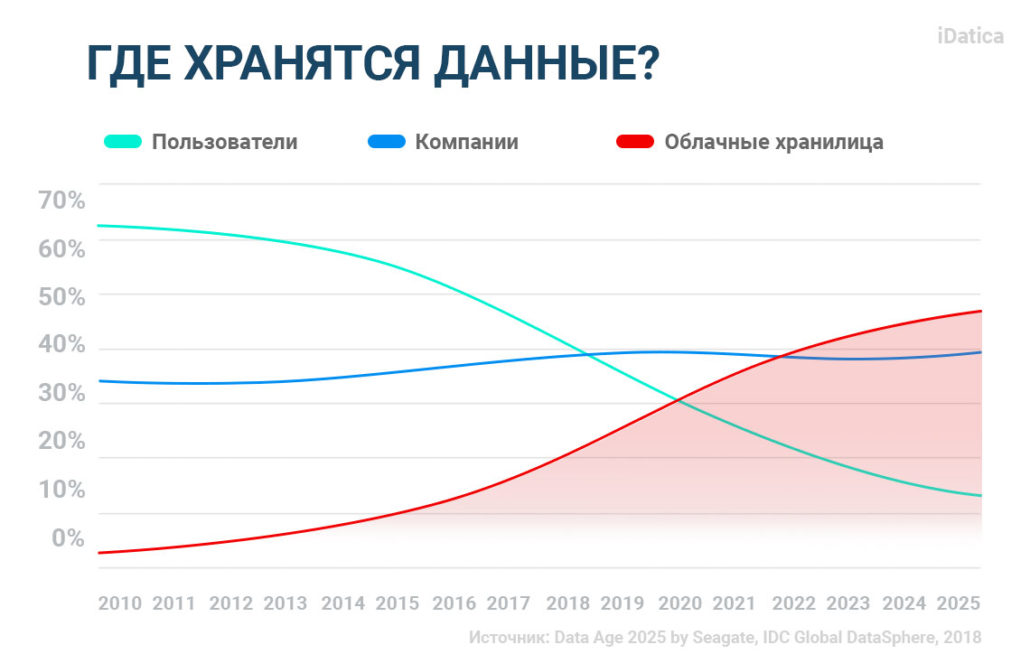
AWS, Microsoft Azure и Google Cloud Platform преобразовали способ хранения и обработки больших данных. Раньше, когда компании хотели запустить приложения, работающие с большим объемом данных, они должны были физически вырастить свои собственные дата-центры. Теперь, с моделью оплаты “по мере потребления”, облачные сервисы обеспечивают гибкость, масштабируемость и простоту использования.
Эта тенденция продолжится и в 2020-х годах, но с некоторыми поправками:
- Гибридная среда. Многие компании не могут хранить конфиденциальную информацию в облаке, таким образом они хранят определенное количество данных на локальных серверах, остальные данные перемещают в публичное облако.
- Мультиоблачная среда. Некоторые компании для закрытия специальных потребностей своего бизнеса предпочитают облачную инфраструктуру, которая позволяет объединить в единое интегрированное пространство инфраструктуру, развернутую у себя и несколько публичных облаков.
2. Машинное обучение продолжит изменять нашу реальность
Играя огромную роль в больших данных, машинное обучение – одна из технологий, которая повлияет на наше будущее радикально.
Машинное обучение становится все более сложным с каждым годом. Нам еще предстоит увидеть весь его потенциал – помимо беспилотных автомобилей, устройств выявления фактов мошенничества или анализа тенденций в ритейле.
Вэй Ли
Вице-президент и генеральный директор компании Intel
Машинное обучение – стремительно развивающаяся технология, она используется для улучшения повседневных задач и бизнес-процессов. Проекты по машинному обучению получили наибольшее финансирование в 2019 году по сравнению со всеми другими системами искусственного интеллекта (ИИ) вместе взятыми:
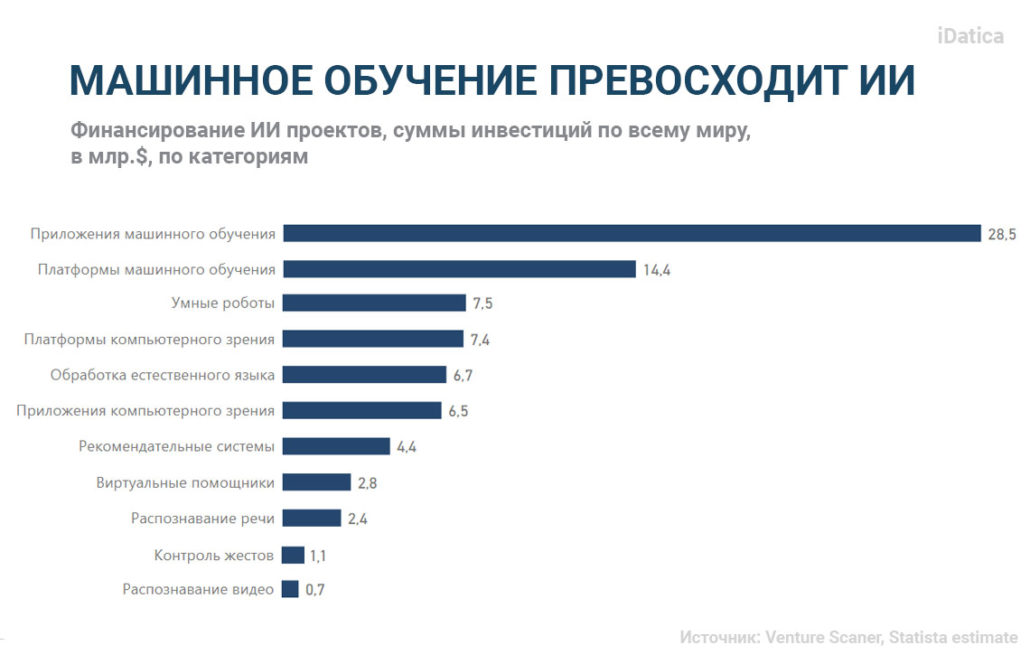
До недавнего времени приложения машинного обучения и искусственный интеллект были недоступны большинству компаний из-за доминирования платформ с открытым исходным кодом. Хотя платформы с открытым исходным кодом были разработаны для того, чтобы сделать технологии ближе к людям, но большинству компаний не хватало навыков для самостоятельной настройки необходимых решений.
Ситуация изменилась, когда стали появляться доступные коммерческие проекты, соединяющие искусственный интеллект и машинное обучение, не требующие сложных конфигураций. Более того, разработчики подобных сервисов предлагают функции, которые в настоящее время отсутствуют на платформах с открытым исходным кодом, например, управление моделью машинного обучения.
Между тем, эксперты считают, что способность компьютеров обучаться на данных значительно улучшится благодаря более продвинутым алгоритмам, более глубокой персонализации и когнитивным сервисам. В результате появятся машины, которые будут более умными, способными считывать эмоции, водить машины, исследовать космос и лечить людей. С одной стороны, умные роботы могут облегчить нашу жизнь. С другой стороны, есть этическая проблема. Такие гиганты как Google и IBM стремятся к большей прозрачности, сопровождая свои модели машинного обучения технологиями, которые отслеживают недочеты и ошибки в алгоритмах.
3. Специалисты по обработке и анализу данных (Data Scientist) и Директора по данным (Chief Data Officer) будут пользоваться высоким спросом
Вакансии специалиста по обработке и анализу массивов данных и директора по данным относительно новые, но потребность в этих специалистах на рынке труда уже высока. Поскольку объемы данных продолжают расти, разрыв между необходимостью и доступностью специалистов по данным уже велик.
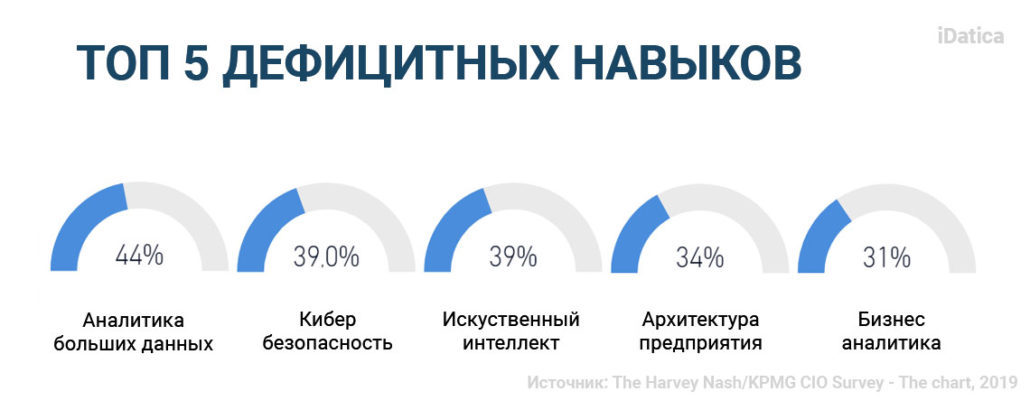
В 2019 году компания KPMG провела опрос 3600 IT-директоров и руководителей технологических компаний из 108 стран и выяснила, что 67% столкнулись с проблемой нехватки навыков, причем тремя наиболее дефицитными навыками были большие данные/аналитика, безопасность и искусственный интеллект.
Если говорить про Россию, то в настоящее время на Headhunter 232 вакансии по запросу “Data Scientist”. Можно сделать вывод что данная специальность востребована и на нашем рынке.
Неудивительно что сегодня профессия специалиста по обработке данных является одной из самых быстрорастущих профессий наряду с инженерами по машинному обучению и инженерами в области больших данных. Большие данные бесполезны без анализа, и специалисты по обработке данных — это те профессионалы, которые собирают и анализируют данные с помощью инструментов аналитики и отчетности, превращая их в эффективные идеи.
Чтобы стать хорошим специалистом по обработке данным, нужно иметь знания в следующих областях:
- Платформы данных и инструменты;
- Языки программирования;
- Алгоритмы машинного обучения;
- Методы обработки данных, такие как построение конвейеров данных (data pipelines), управление ETL-процессами и подготовка данных для анализа.
Стремясь улучшить свою деятельность и получить конкурентное преимущество, компании готовы платить более высокие зарплаты таким специалистам.
Кроме того, чтобы восполнить недостающие знания и навыки, компании также готовы выращивать специалистов по обработке данных внутри компании. Этим специалистам не привыкать к созданию передовых аналитических моделей, хотя сами по себе они находятся за пределами области аналитики. Тем не менее с помощью технологий они могут выполнять обработку больших объемов данных, не имея профильного университетского образования.
С другой стороны, ситуация с директором по данным не совсем ясна. Директор по данным – руководитель высшего звена, отвечающий за доступность, целостность и безопасность данных в компании. По мере того, как все больше владельцев бизнеса осознают важность этой роли, найм директора по данным становится нормой, например согласно опросу Big Data и AI Executive 2019 проведенному NewVantage Partners – 67,9% крупных компаний уже имеют директора по данным.
Тем не менее, позиция директора по данным остается нечетко определенной, особенно с точки зрения обязанностей или, если быть более точным, как эти обязанности должны быть разделены между директором по данным, специалистами по обработке данных и IT-директорами. Это одна из ролей, которая не может быть универсальной для всех, она зависит от потребностей бизнеса конкретной компании, а также от их опыта в цифровых технологиях. Позиция директора по данным значительно поменяется в будущем и будет развиваться по мере того, как компании станут чаще применять данные в бизнес-процессах.
4. Вопрос конфиденциальности данных останется актуальной проблемой
Безопасность данных и конфиденциальность всегда были насущными проблемами. Постоянно растущие объемы данных создают дополнительные проблемы для их защиты от вторжений и кибератак, поскольку уровни защиты данных не успевают за темпами роста объемов.
Есть несколько причин, почему возникают проблемы безопасности данных:
- Недостаточные знания и навыки по обеспечению безопасности, это вызвано отсутствием программ обучения и профессиональной подготовки. По данным Cybercrime Magazine к 2021 году на рынке будет 3,5 миллиона незанятых позиций в области кибербезопасности, это данные для Американского рынка, но без сомнения в России вопрос будет стоять не менее остро.
- Эволюция кибератак. Методы, используемые хакерами, с каждым днем становятся все сложнее.
- Нерегулярность в соблюдении стандартов безопасности. Несмотря на то, что правительства принимают меры для стандартизации правил защиты данных (например, 152-ФЗ РФ “О персональных данных” и правила обработки персональных данных в Европе GDPR), большинство компаний по-прежнему игнорируют стандарты безопасности данных.
Статистика ярко демонстрирует масштаб проблемы. По данным Сбербанка потери экономики РФ в 2019 году от кибератак оцениваются в 2,5 триллиона руб. Что касается данных по всему миру Statista подсчитала потери от кибератак, они составили 3500 миллиона долларов 2019 году.
Еще один повод для беспокойства — это репутация. Хотя многие организации рассматривают политику конфиденциальности данных в качестве юридической процедуры по умолчанию, пользователи поменяли свое отношение к этому вопросу. Они понимают, что на карту поставлена их личная информация, поэтому обращаются к тем компаниям, которые обеспечивают прозрачность и контроль данных на уровне пользователей.
Неудивительно, что руководители компаний считают конфиденциальность данных своим главным приоритетом наряду с кибербезопасностью и этикой данных. По сравнению с 2018 годом компании инвестировали в пять раз больше в кибербезопасность в 2019 году:
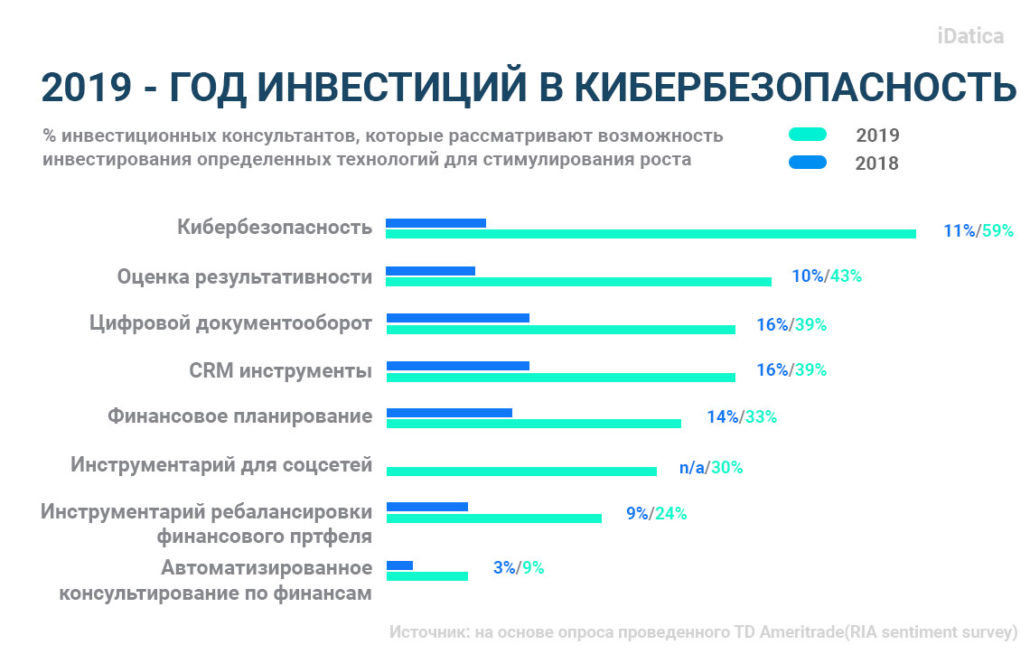
5. Быстрые данные и действенные данные выйдут на первый план
Еще один прогноз о будущем больших данных связан с появлением так называемых «быстрых данных» и «действенных данных».
В отличие от больших данных, обычно использующих базы данных Hadoop и NoSQL для анализа информации в пакетном режиме, быстрые данные позволяют обрабатывать потоки информации в режиме реального времени. Благодаря такой обработке потока данные могут быть проанализированы быстро всего за одну миллисекунду. Такой процесс приносит больше пользы компаниям, они могут принимать бизнес-решения и принимать меры сразу же после получения данных.
Быстрые данные также влияют на пользователей, делая их зависимыми от взаимодействия в реальном времени. По мере того, как компании становятся все более технологичными, улучшают качество обслуживания клиентов, пользователи ожидают, что доступ к данным будет осуществляться моментально. Более того, они хотят доступ к персонализированным данным. В исследовании, приведенном выше IDC, прогнозирует, что к 2025 году почти 30% глобальных данных будут в режиме реального времени.
Действенные данные — это недостающее звено между большими данными и ценностью для бизнеса. Как упоминалось ранее, большие данные сами по себе бесполезны без анализа, поскольку они слишком сложны, многоструктурны и объемны. Обрабатывая данные с помощью аналитических платформ, компании могут сделать информацию точной, стандартизированной и действенной. Эти сведения помогают компаниям принимать более обоснованные бизнес-решения, осуществлять свою деятельность и разрабатывать более масштабные сценарии использования данных.
Будущее больших данных, что ждет организации
Будущее больших данных, будучи пугающим и увлекательным одновременно, обещает изменить методы работы компаний в финансовой, медицинской, производственной и других отраслях.
Огромный размер больших данных может создать дополнительные проблемы в будущем – риски конфиденциальности информации и безопасности, нехватка кадров в области данных и трудности в хранении и обработке данных.
Однако эксперты сходятся во мнении, что большие данные будут иметь все большую ценность. Это приведет к появлению новых профессий и даже целых отделов, отвечающих за управление данными в крупных компаниях. Появятся новые регулирующие структуры и стандарты поведения, так как компании все еще продолжают использовать личные данные пользователей. Кроме того, большинство компаний перейдут от создания данных к использованию быстрых и действенных данных, принимая на их основе бизнес-решения.
Наша компания занимается сбором данных посредством парсинга. Если у вас есть задача по парсингу, которую вы бы хотели обсудить, свяжитесь с нами через форму обратной связи, напишите в телеграм или позвоните по телефону.



