
В этой статье на рассмотрим на примере, по шагам, как парсить данные из интернет-магазина при помощи расширения от iDatica.
- Парсить будем сайт Amazon, эту страницу;
- Для начала, установите расширение в браузер google chrome или microsoft edge.
Откройте сайт в браузере (статья на примере google chrome, но ms edge все тоже самое), откройте инструменты разработчика (F12), сбоку разместите окно расширения:
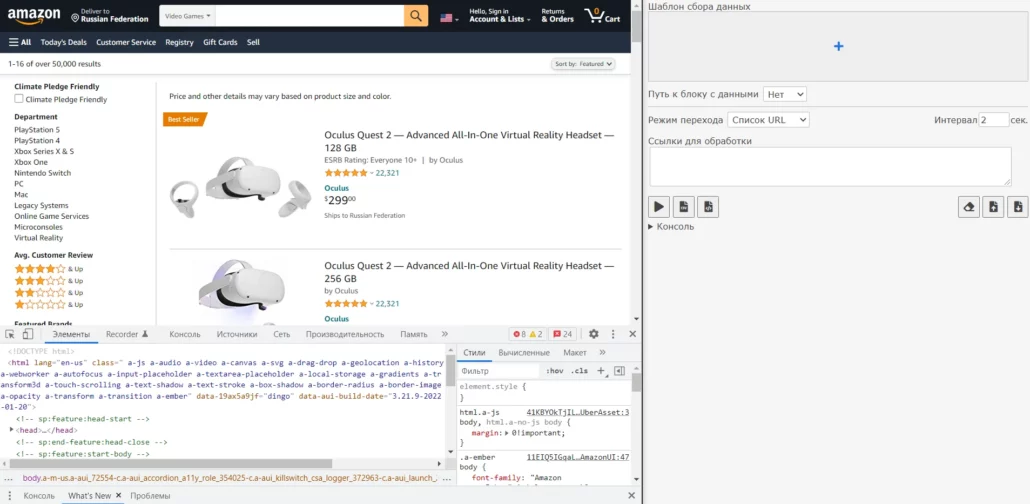
Теперь нам необходимо создать первый столбец с данными, пусть это будет поле “Название товара”. Нажмите на “+” в расширении:

появится поле с настройками столбца, назовите поле:
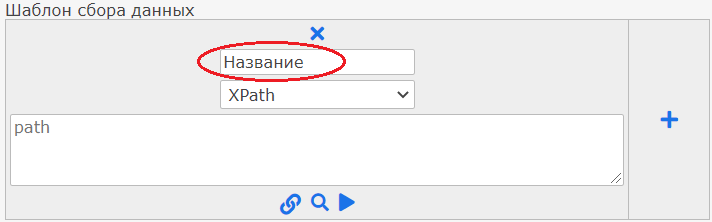
В столбце есть:
- Выбор селектора для поиска данных xpath или css;
- Поле для запроса который будет вести к нужным данным – этот путь говорит программе какие данные нужно собрать на сайте и поместить в этот столбец. Как составлять запросы рассказывается в этой статье;
- Кнопка для поиска пути к данным – запрос к данным составляется автоматически;
- Кнопка показа какие элементы на странице находятся по введенному запросу;
- Кнопка показа какие данные находятся на странице по этому запросу и их количество.
Давайте получим названия товаров. Для этого кликните правой клавишей мыши на названии и выберите в контекстном меню “посмотреть код”:
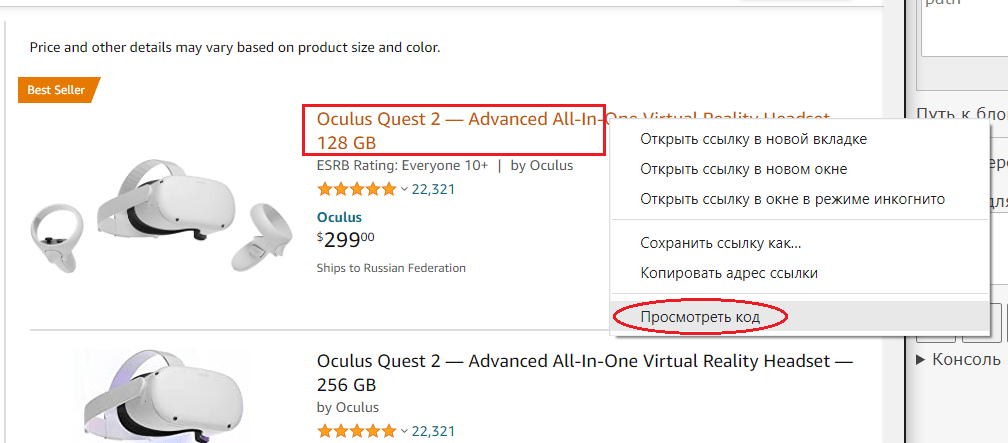
Фокус в панели разработчика перейдет к месту в коде сайта на котором расположен заголовок:
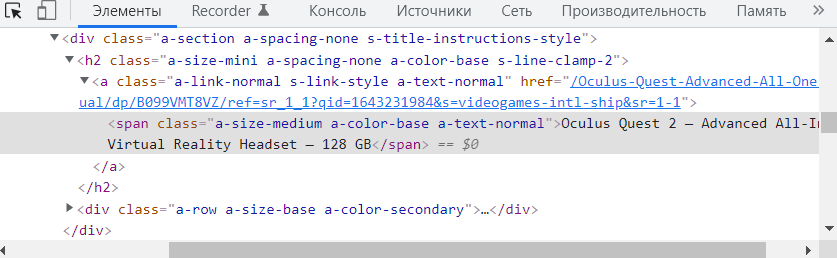
Видим заголовок h2, в него вложена ссылка a, в ссылку вложен элемент span в котором содержится текст заголовка. Так как заголовок h2 является уникальным элементом на странице построим запрос xpath от него:
//h2/a/spanВыберем селектор – xpath. Запрос поместим в соответствующее поле. Нажмем на пиктограмму лупы, чтобы проверить, что находит парсер на странице (должно быть активно окно браузера с сайтом) – найденные значения будут подсвечены:
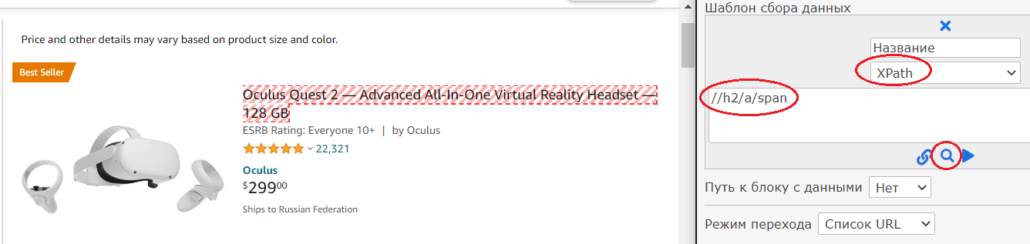
Следующим шагом сделаем столбец в который будет собираться цена. Обратите внимание, что цена есть не у всех товаров:
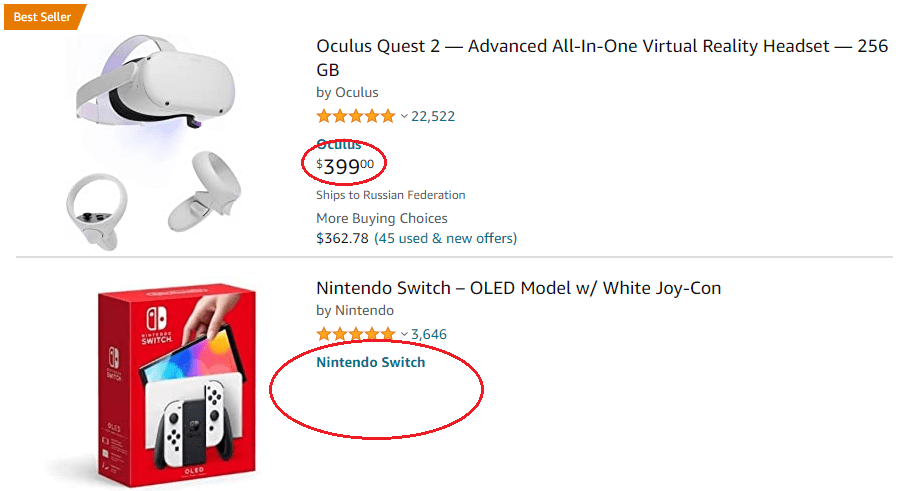
В текущей конфигурации парсер “не знает” где начинаются и заканчиваются данные относящиеся к одному товару, значит если спарсить названия и цены, то в финальной выгрузке данные будут идти друг за другом без пропусков в тех ячейках где данных нет:

Чтобы данные относящиеся к одному товару располагались в одной строке, нужно указать парсеру на начало и конец блока одного товара. Для того, чтобы найти блок одного товара в коде, начните подниматься вверх по коду, наводите курсор в инспекторе задач на код, обратите внимание блоки данных при этом будут подсвечиваться:
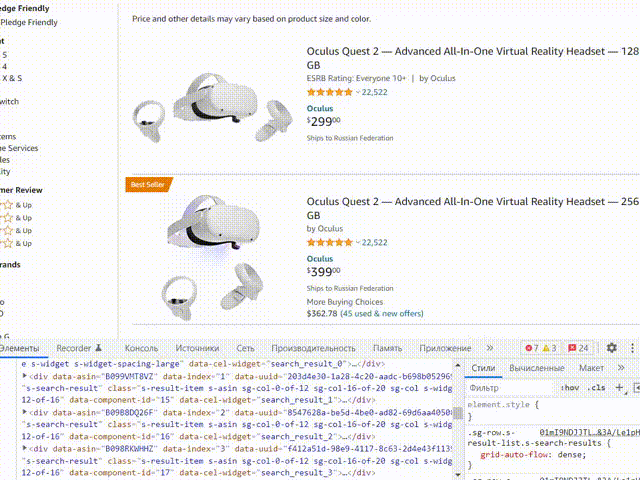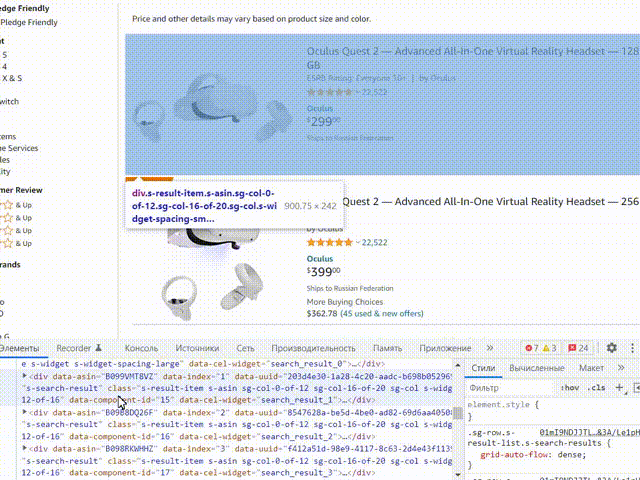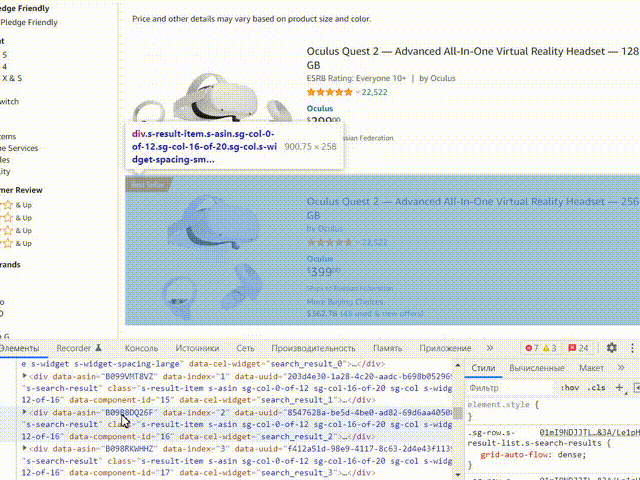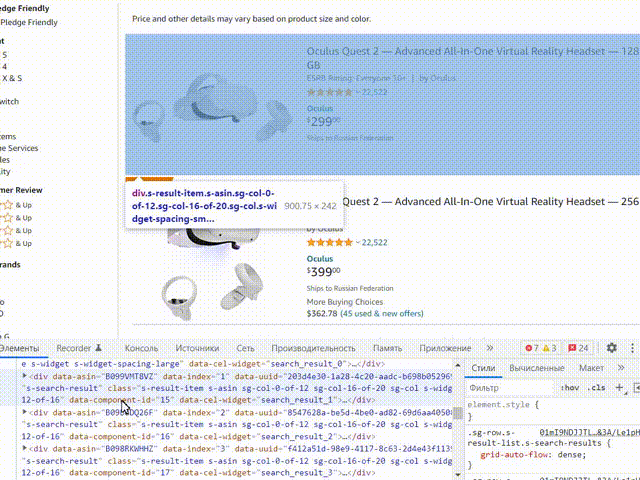
Наша задача найти верхний блок который отвечает за товар, такие блоки будут идти друг за другом и при наведении будут подсвечивать карточку товаров. Напишем запрос к этому блоку, я решил использовать стиль .s-widget-spacing-small. Выбираем путь к блоку данных: CSS, пишем туда нужный стиль:
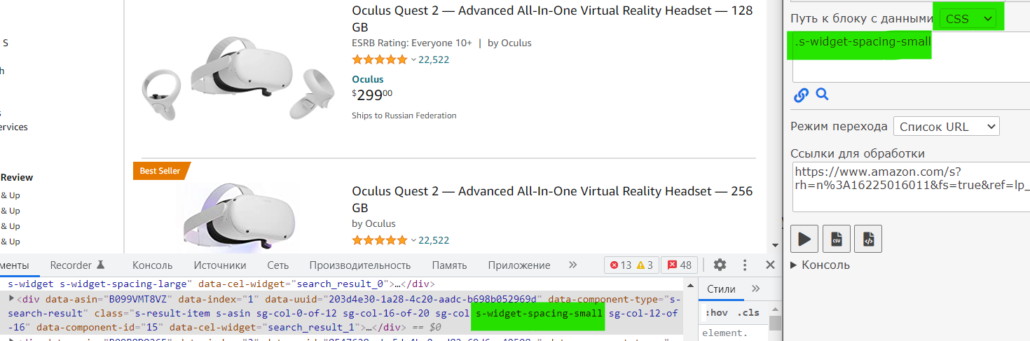
Нажмем на пиктограмму лупы и проверим, что парсер верно определяет блоки с карточками товара:
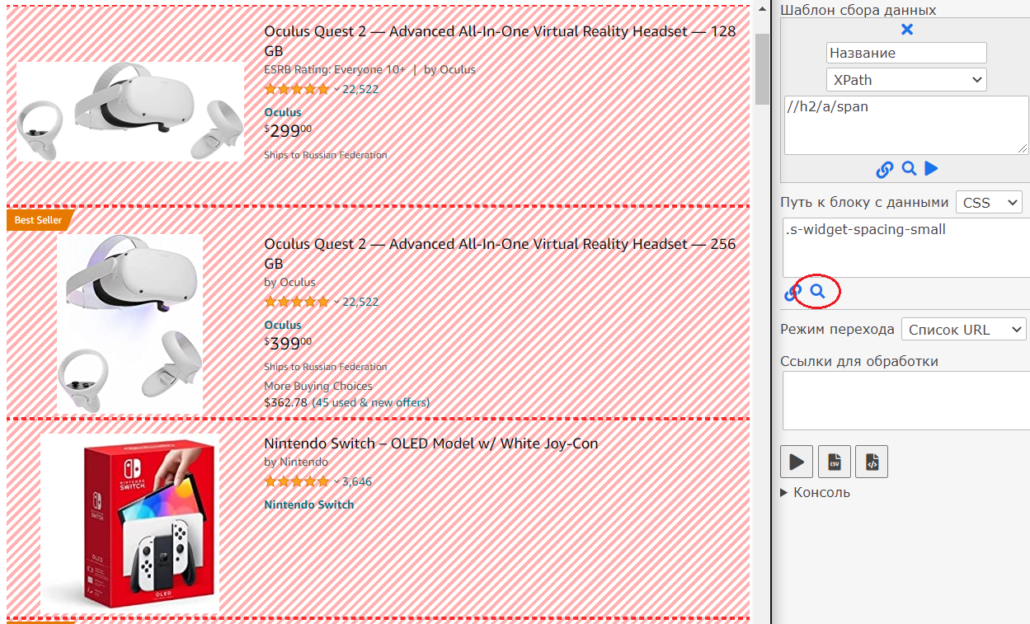
Парсер подсветил карточки товара, значит данные будут собраны как нам нужно. Давайте проверим, найдем блок цены. При этом обратите внимание, что в Амазоне в карточке товара может быть несколько цен, значит нужно выбрать блок с правильной и спуститься до нужного элемента:
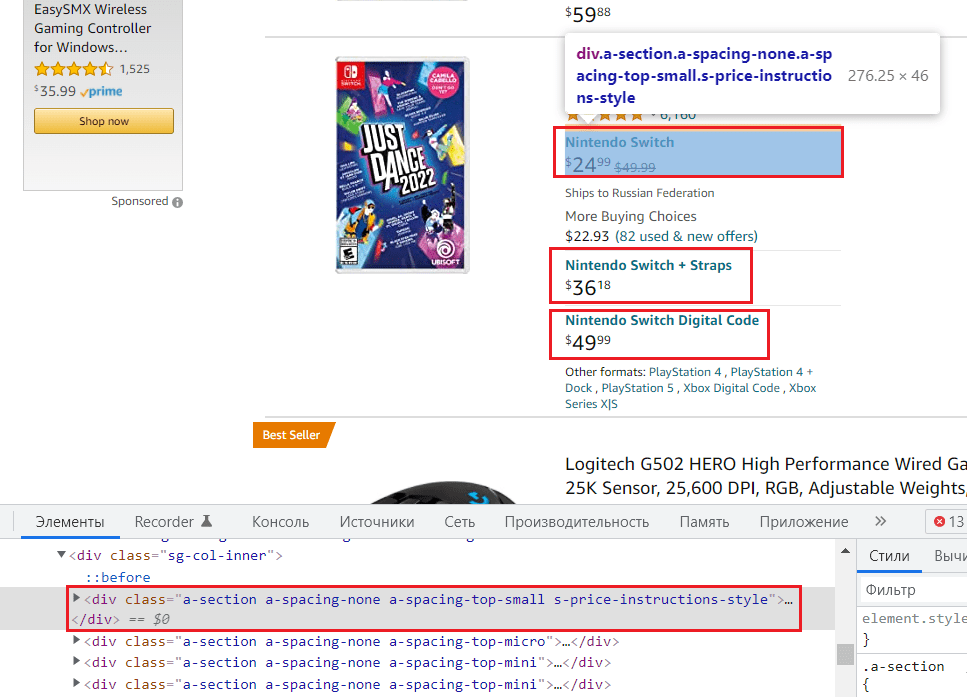
Получается так – ищем div с классом s-price-instructions-style, и спускаемся ниже, до нужного элемента. Так как после элемента a у некоторых товаров есть 2 элемента span (зачеркнутая цена), нужно указать, чтобы парсер спускался в первый span[1], в противном случае парсер соберет данные из обоих элементов span. Далее можно увидеть, что цена дублируется в коде, поэтому укажем, чтобы парсер искал цену в элементе span aria-hidden=”true”.
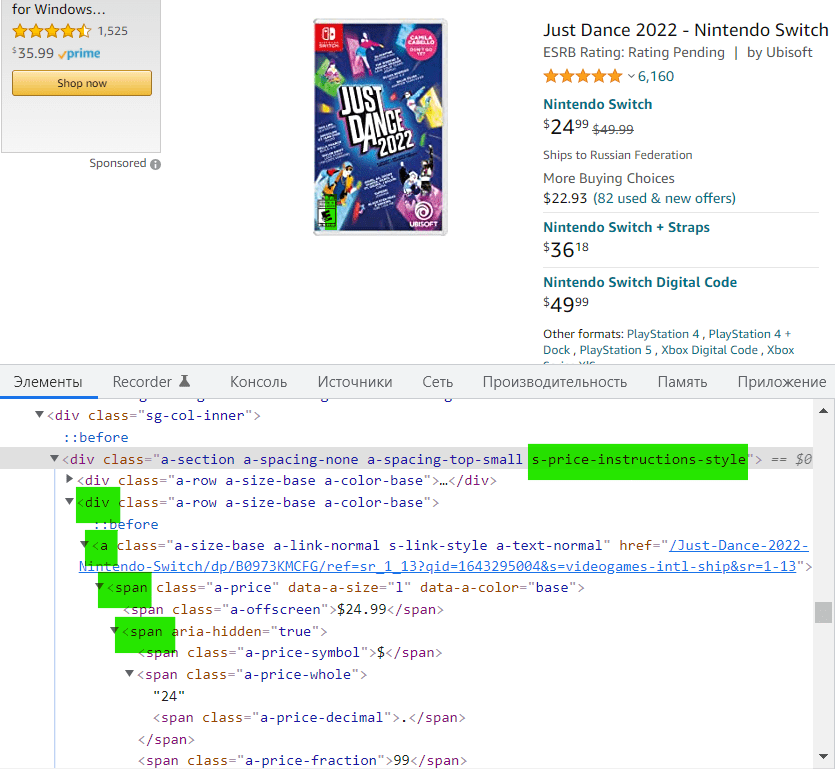
//div[contains(@class,"s-price-instructions-style")]/div/a/span[1]/span[@aria-hidden="true"]Посмотрим какие данные нашел парсер по этому запросу, нажмем на пиктограмму кнопки play (должно быть активно окно браузера с сайтом), откроется окно в котором отобразятся найденные значения:
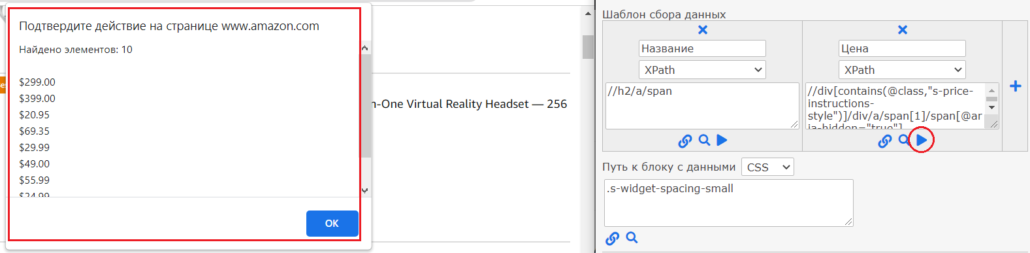
Да, это наша цена и их на странице 10 штук, все верно.
Далее добавим, старую цену, как уже выяснили это соседний элемент span поэтому просто меняем 1 на 2:
/div[contains(@class,"s-price-instructions-style")]/div/a/span[2]/span[@aria-hidden="true"]Далее получим картинку, от div с классом s-product-image-container спустимся до элемента img
div[class*="s-product-image-container"] imgДобавим еще пользовательский рейтинг, укажем просто стиль css:
.a-icon-star-smallТеперь добавим код кнопки далее, режим перехода установите на “Кнопка далее” и добавим стиль этой кнопки:
.s-pagination-next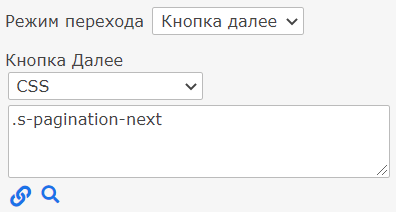
На этом будем считать, что это все данные которые нужно собрать и можно запускать парсер. Нажимаем на play, парсим нужное количество страниц, останавливаем парсер или ждем пока закончится каталог, и нажимаем на кнопку получения итогового файла:

Я хочу получить файл в формате csv, чтобы открыть его в excel. Разделитель (символ отделяющий столбцы) можно указать любой, по умолчанию “;”.
И итог нашей работы, таблица с корректными данными:
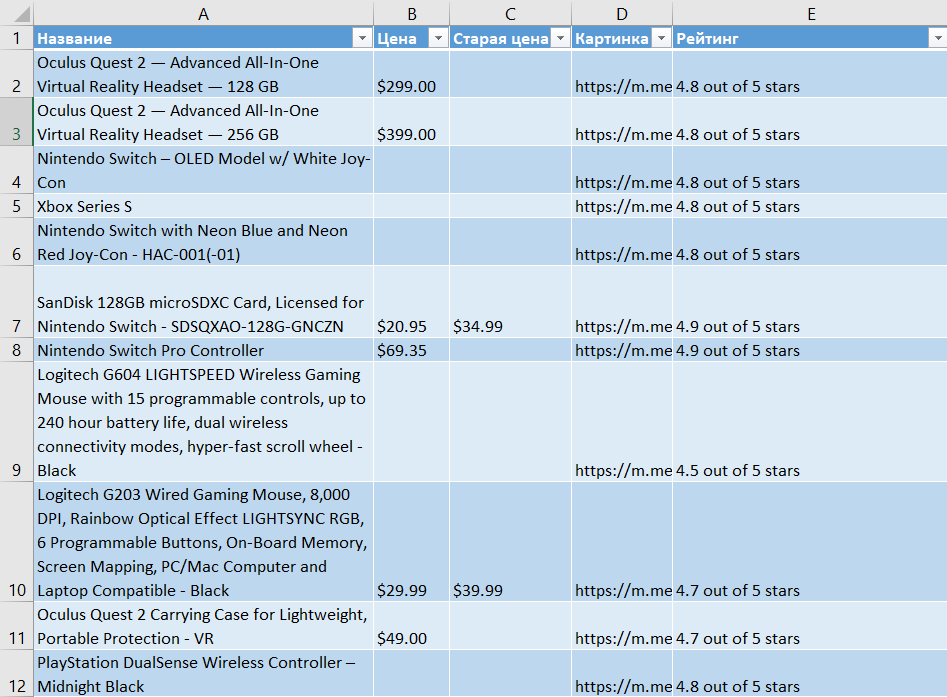
Шаблон для парсинга Amazon





