
XPATH и CSS на простых примерах
Данная статья написана, чтобы помочь быстро разобраться с тем, как парсить данные при помощи расширения от iDatica. Статья рассчитана на людей не знакомых с Xpath и CSS. Рассмотрим совсем немного теории и базовый (для парсинга данных) синтаксис которые позволят понять как собирать данные с подавляющего большинства сайтов.
Применение Xpath для парсинга
Прежде всего, нужно разобраться, что такое Xpath (XML Path Language) — это язык запросов к элементам хml-разметки. Это означает, что отправляя определенным образом составленный запрос, вы получаете в ответ нужные данные. Простая аналогия — адрес в строке браузера или путь в эксплорере до нужной папки, набирая правильный путь вы попадаете на нужный сайт или в нужную папку. С Xpath так же — пишем путь и попадаем к нужным данным, только в отличии от строки браузера Xpath применяем для поиска. И в нашем случаем для поиска по xml документам в формате html, другими словами по коду на котором построен сайт.
Если вы нажмете на пустом месте сайта правой клавишей мыши и выберете в контекстном меню «исходный код сайта» или «посмотреть код страницы», в разных браузерах по разному, вы как раз попадете на страницу с кодом из которого парсер извлекает данные.
Например, код может выглядеть так:
<html>
<body>
<div>Заголовок
<H1>Название</H1>
</div>
<div>Описание</div>
<div>Характеристики
<span class="text">Высота</span>
<span class="text">Ширина</span>
<span>Цена</span>
</div>
<a href="https://site.com/pic.png">Фотография товара</a>
</body>
</html>Как видно код представляет собой древовидную структуру, в которой каждый элемент определенным образом размечен, наша задача заключается в том, чтобы указать парсеру путь к нужному нам элементу.
Дальнейшие действия будем рассматривать на примере нашего каталога баз данных по этому адресу.
Для дальнейшей работы нам понадобится инструмент разработчика встроенный в браузер, в Chrome — контекстное меню — посмотреть код, в Firefox — контекстное меню — исследовать.
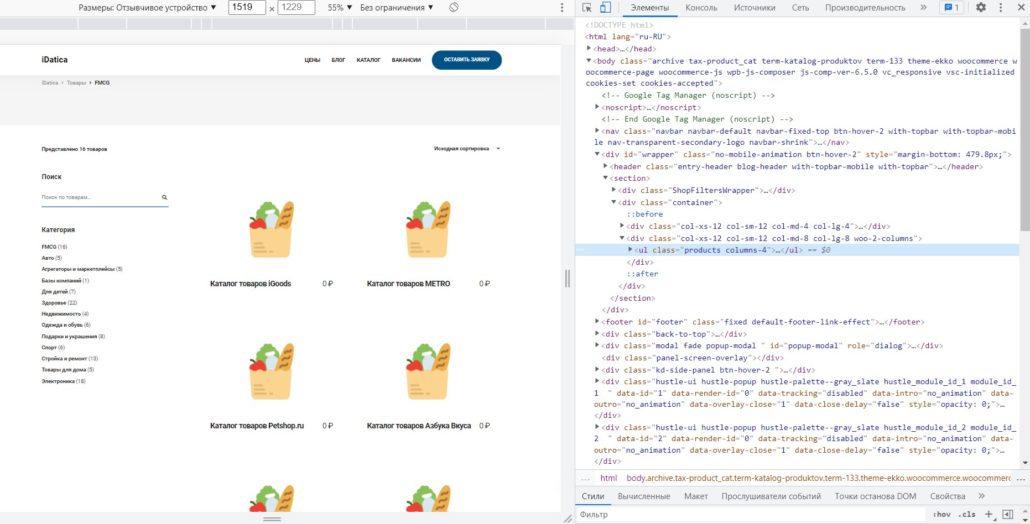
Итак, давайте найдем путь до названия карточки товара:

Кликаем на название товара правой клавишей мыши — откроется контекстное меню, выбераем — «посмотреть код» — нашли нужный элемент в коде. Как можно определить путь до него? Как и в случае с проводником опускаемся из верхней категории до «нужной папки». Верхняя директория «html», далее «body» , далее несколько блоков «div», «ul», если на каком-то уровне несколько блоков с одинаковым названием, то в квадратных скобках пишем какой элемент по счету нам нужен:
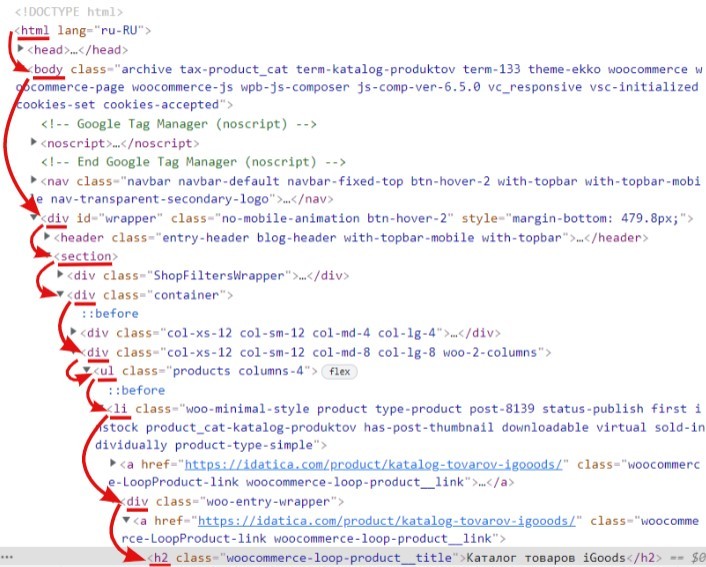
Если записать, этот путь то получится:
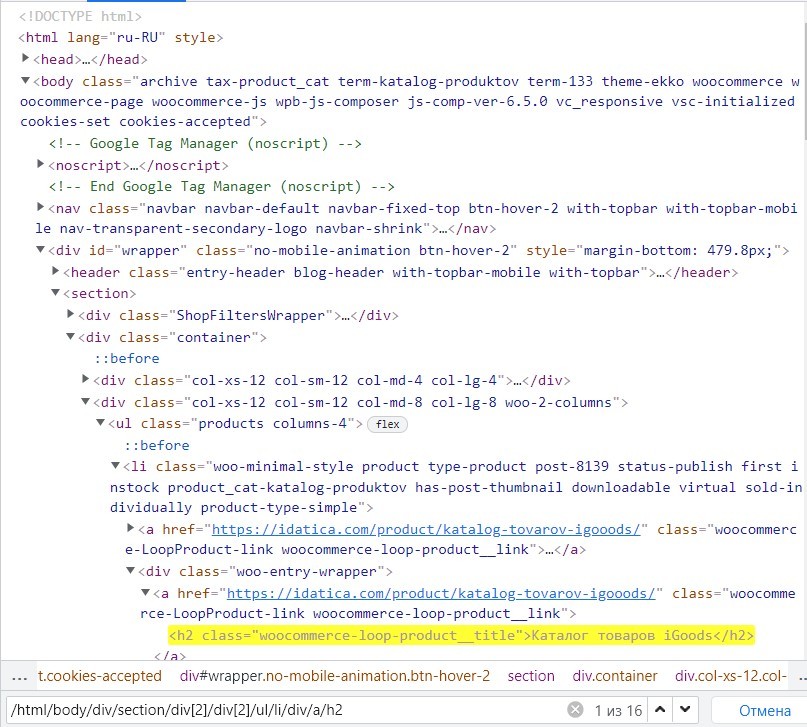
/html/body/div/section/div[2]/div[2]/ul/li/div/a/h2Этот путь можно проверить в том же инструменте разработчика, нажав Ctrl+F и записать путь:
Можно проверить путь в расширении iDatica, нажав на пиктограмму поиска:
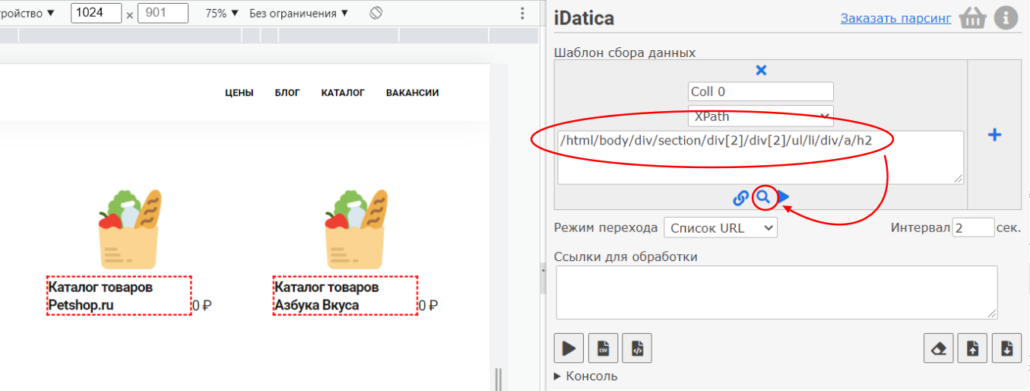
Если в расширении нажать на пиктограмму play, то программа покажет все элементы которые нашла на странице по этому пути — в нашем случае это все названия. Если нажать на кнопку парсинга и сохранить результат — то вы спарсите все названия, поздравляю — вы собрали первые данные!
Как быть с остальными элементами на странице? Так же — пишем путь и получаем данные. Можно получить этот путь сразу в инструменте разработчика — кликнуть правой клавишей мыши на нужном элементе в коде, выбрать — копировать и выбрать xpath:
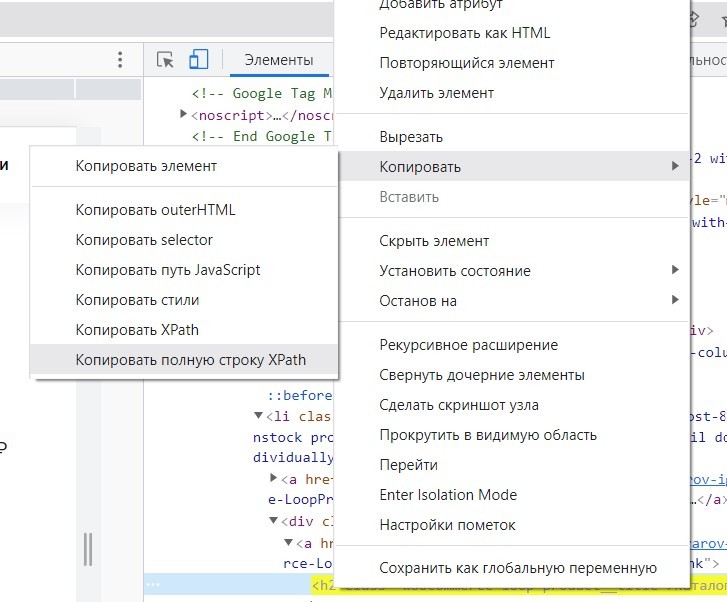
Можно получить этот путь сразу в расширении, нажав на пиктограмму ссылки и кликнув на нужный элемент на странице.
Работать с такими длинными путями не удобно и не на всех сайтах можно получить путь сразу ко всем элементам, в некоторых случаях его придется дорабатывать изучая особенности структуры сайта. Но составить путь к данным на много проще и быстрее. Тут нам нужно познакомится с синтаксисом Xpath.
Синтаксис Xpath
Относительный путь
Двойной слеш // — означает относительный путь и позволяет найти все варианты того, что вы ищете на странице. Таким образом — тк мы искали конечный элемент h2, то запись «//h2», даст тот же результат, что и длинный путь который мы написали в начале:
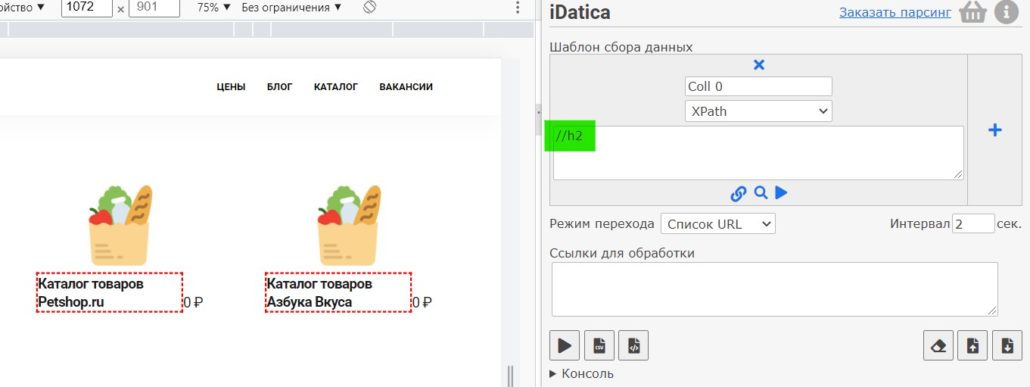
Таким образом можно обращаться к любым элементам на странице.
Условия поиска
Хорошо, идем дальше, скачаем цену. В коде она не обозначена одним элементом, как заголовок h2, цена находится в строковом элементе span, но их много на странице и они отвечают за разные данные, как нам обратиться к нужному?
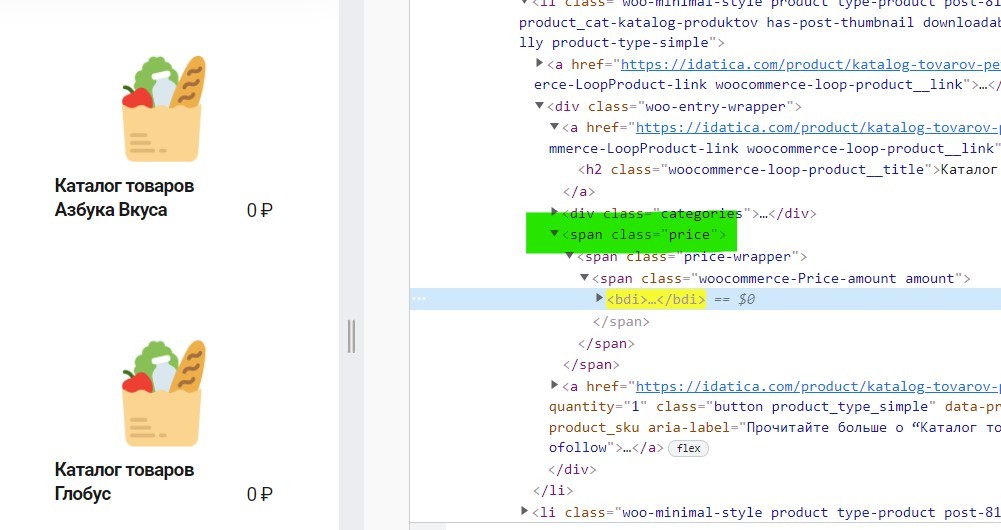
Если посмотреть на код то можно увидеть, что многие элементы на странице содержат атрибуты и названия, например, элемент цены — «span» имеет атрибут «class» с названием «price» — вот к этому названию мы и сможем обратиться. Для этого в квадратных скобках, после указания элемента который мы ищем, нужно прописать условия поиска этого элемента:
//span[@class="price"]Такая конструкция найдет все вложенные в этот элемент данные.
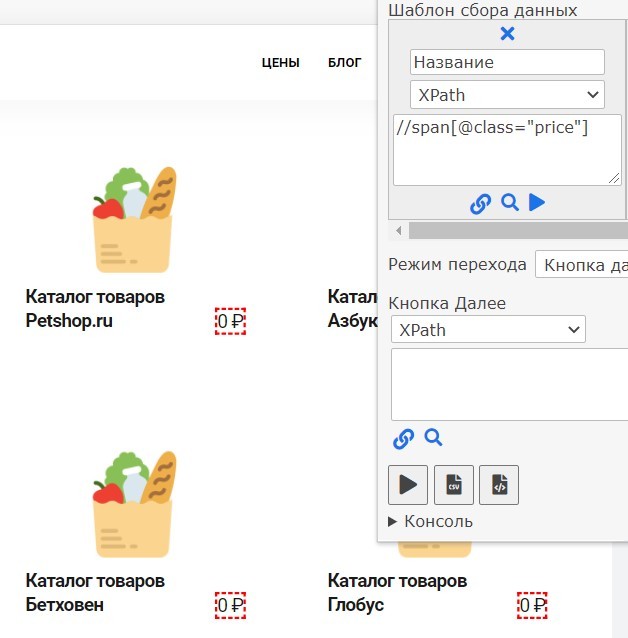
Таким образом можно обращаться ко всем элементам на странице, //div — будет искать во всех элементах «div», //a — во всех элементах «a» итд.
//* — будет искать во всех элементах
Поиск по части вхождения
Бывают ситуации, когда название атрибута не уникально, как например в списке категорий:
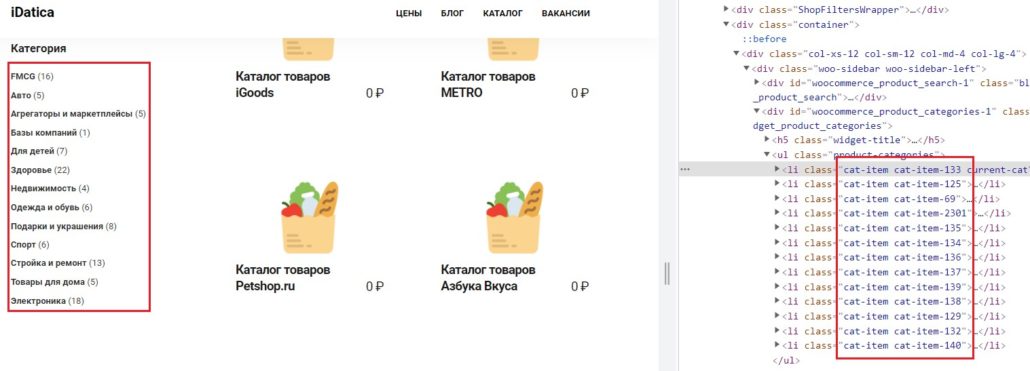
В таком случае можно искать нужные элементы по части вхождения, в данной ситуации — «cat-item», такие элементы найдет команда — «contains», обратите внимание в случае с «contains» элемент пишется в скобках и через «,» вместо «=».
//*[contains(@class,"cat-item")]При этом парсер захватит весь текст внутри элемента, т.е. и название и количество, чтобы получить только название нужно сузить поиск, указать, что внутри нужно взять только значения элемента «а»:

Необходимо через слеш указать дальнейший путь, вложенность может быть такой, какая вам необходима, в нашем случае:
//li[contains(@class,"cat-item")]/aСоответственно, если нужно получить только количество — обращаемся к элементу span:
//li[contains(@class,"cat-item")]/spanЕсли нужно получить данные из определенного элемента по счету, указываем номер элемента в квадратных скобках:
//*[contains(@class,"cat-item")][5]Чтобы получить первый элемент используем индекс — [1]
Получить только последний элемент — last():
/*[contains(@class,"cat-item")][last()]Поиск по тексту
Бывают ситуации, когда можно привязаться только к тексту на странце, в таком случае используем «text» позволяющий находить элементы с нужным текстовым вхождением. Например такая конструкция найдет все элементы в которых есть слово «Каталог»:
//*[contains(text(),'Каталог')]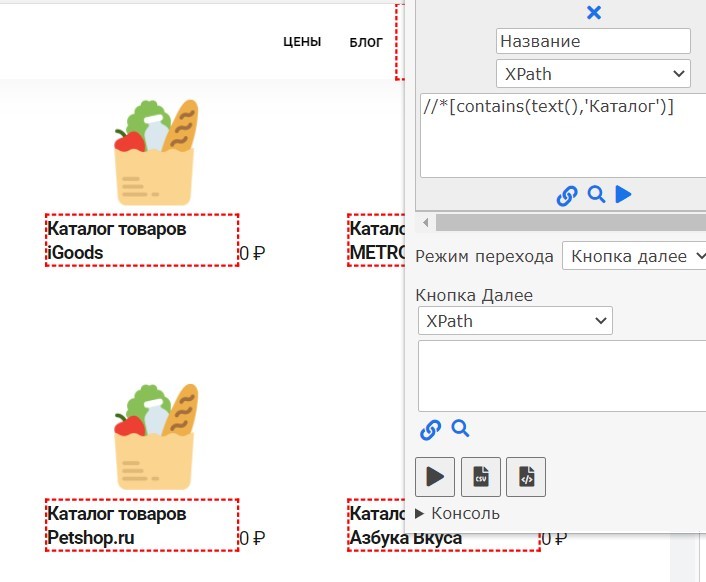
Родственные связи xpath
Можно сказать, что это уже продвинутые команды, они не часто требуются, но бывают ситуации когда они не заменимы. Html код представляет из себя древовидную структуру в которой одни элементы вложены в другие и xpath позволяет использовать вложенность элементов, чтобы поднимать или опускаться по такому дереву, для поиска нужного элемента. В терминах языка xpath элементы, которые содержат другие — являются предками (ancestor) по отношению к во всем вложенным в него. Вложенные в свою очередь — являются его потомками (descendant). Синтаксис использования будет такой — //начальный элемент/команда родственной связи::тег(фильтр) искомого элемента.
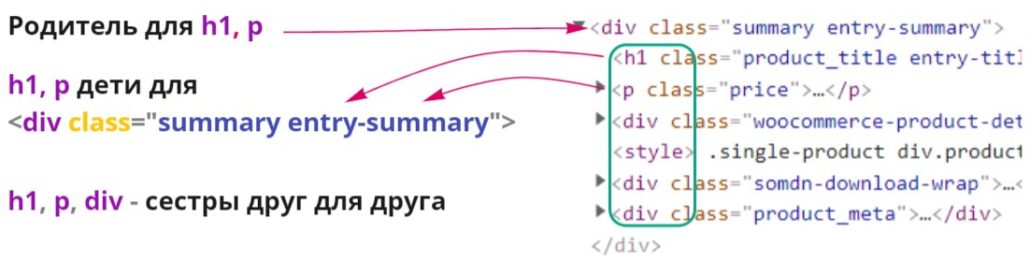
Родственные связи удобно использовать тогда, когда нет возможности привязаться к элементу, например класс не уникален, но рядом есть элемент за который можно «зацепиться». В приведенном примере можно найти нужные элементы проще, указывая вложенность последовательно перечисляя элементы, рассмотрим код в качестве примера работы команд. На примере этой страницы.
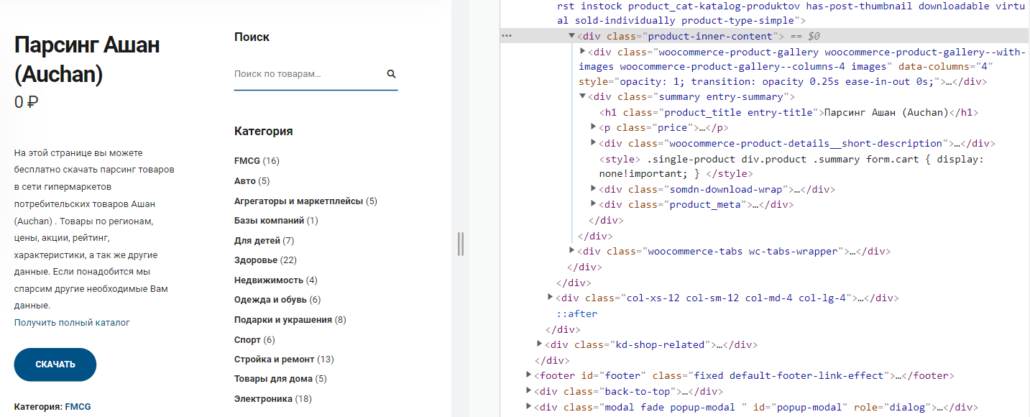
Sibling — cестринский элемент
Sibling перемещается к соседним элементам, расположенным на одном уровне. Бывают двух типов — preceding-sibling — сестринский элемент расположенный выше указанного и following-sibling – сестринский элемент, расположенный ниже указанного.
Например, получим цену отталкиваясь от заголовка:
//h1/following-sibling::pИ наоборот, получим заголовок отталкиваясь от цены:
//p[@class="price"]/preceding-sibling::h1Parent и child — родитель и ребенок
Команды позволяющие опускаться или подниматься на уровень. Уровней вложенности может быть несколько, если вам нужно спуститься или подняться на несколько уровней, используйте / в качестве разделителя.
Child — дети, элемент который является вложенным на один уровень вниз от родителя. Например, найдем цену от родительского элемента div:
//div[contains(@class,"entry-summary")]/child::pParent — родительский элемент позволяющий подниматься на уровень выше, находиться от вложенного элемента. Например, получим название категории с количеством товаров, отталкиваясь от названия категории:
//*[contains(text(),'Электроника')]/parent::liParent так же можно заменить на /.. те код выше будет выглядеть так:
//*[contains(text(),'Электроника')]/..Синтаксис и применение CSS для парсинга
CSS локаторы или стили, еще один вариант для получения данных с сайта. CSS удобно использовать тем, что можно указать класс элемента (если он уникален). Вернемся для примеров на эту страницу. Например, чтобы получить все названия достаточно написать стиль с точкой перед ним. Стиль можно посмотреть в инструменте разработчика на вкладке стили (не забудьте в расширении в типе селектора выбрать CSS):
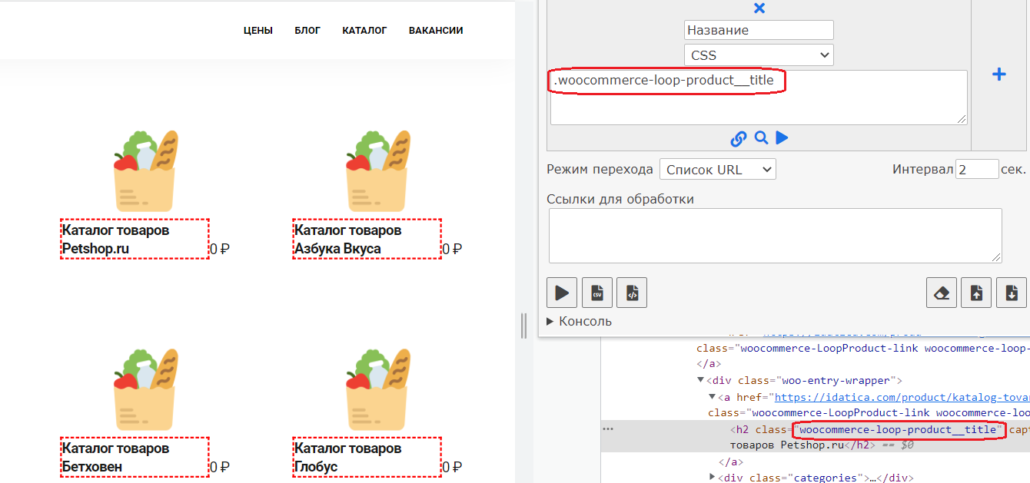
.woocommerce-loop-product__titleЧтобы получить цену, достаточно указать ее стиль: .price попробуйте, это просто.
id для поиска нужных данных
Далее перейдем на страницу поисковой выдачи, тк она содержит нужные нам элементы. Если в коде элементы размечены id, то достаточно указать символ # и значение id:
#hdtbMenus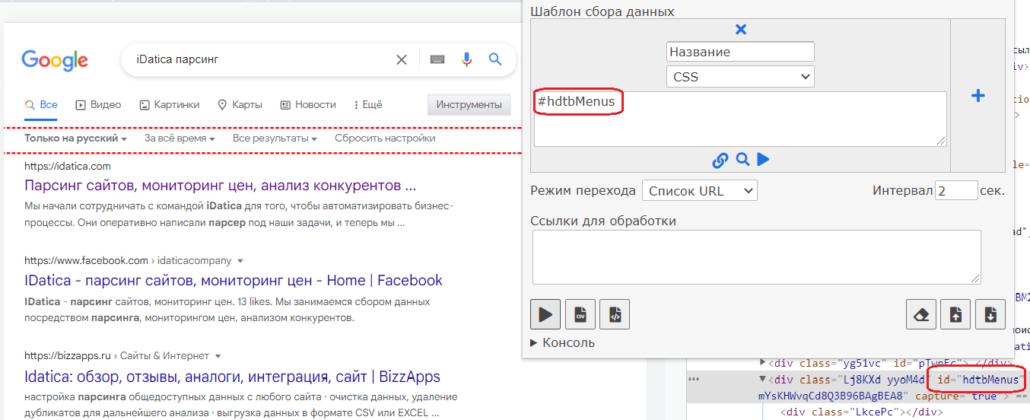
Поиск по значению атрибутов
Поиск по значению атрибутов применяется тогда, когда нет уникального класса или id является сгенерированным. Синтаксис: элемент[атрибут=»значение атрибута»]. Например:
div[class="KTBKoe"]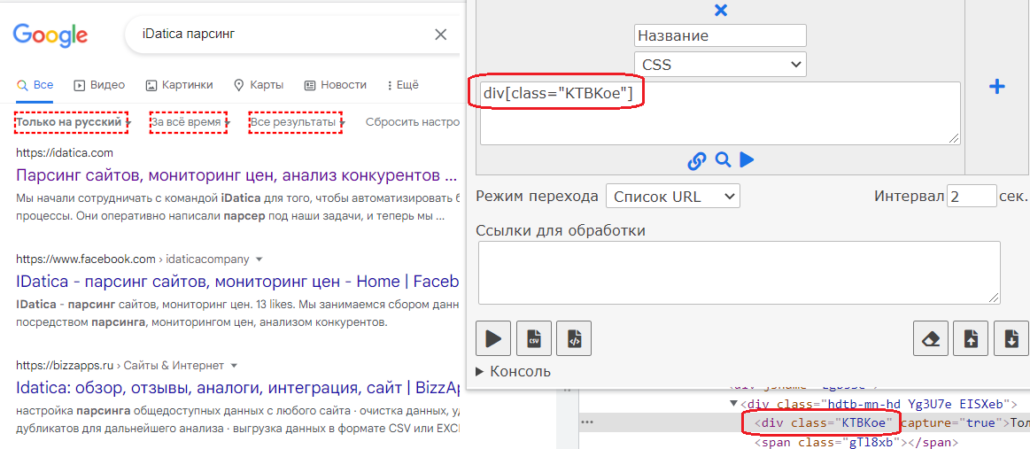
Поиск по частичному вхождению
Бывают случаи когда нужно использовать значение атрибута не циликом, а частично, например в случае когда множество элементов содержит общую часть. Рассмотрим на примере кода написаного выше, все предложенные варианты дадут тоже результат.
Если известна часть значения распологающаяся в любой его части, используется *
div[class*="TBKo"]Если нужно искать по начальной части значения, испоьзуется ^
div[class^="KTB"]Если нужно искать по конечной части значения, испоьзуется $
div[class$="Koe"]Если в значении слова разделены пробелом одно из которых точно известно, используется ~
div[class~="KTBKoe"]Родственные связи CSS
Принцип тот же, что и в xpath. Если нужно получить значение вложеного элемента, на уровень ниже используем >
div[class="Lj8KXd yyoM4d"]>spanЕсли нужно получить значение вложеного элемента, на уровень ниже используем пробел
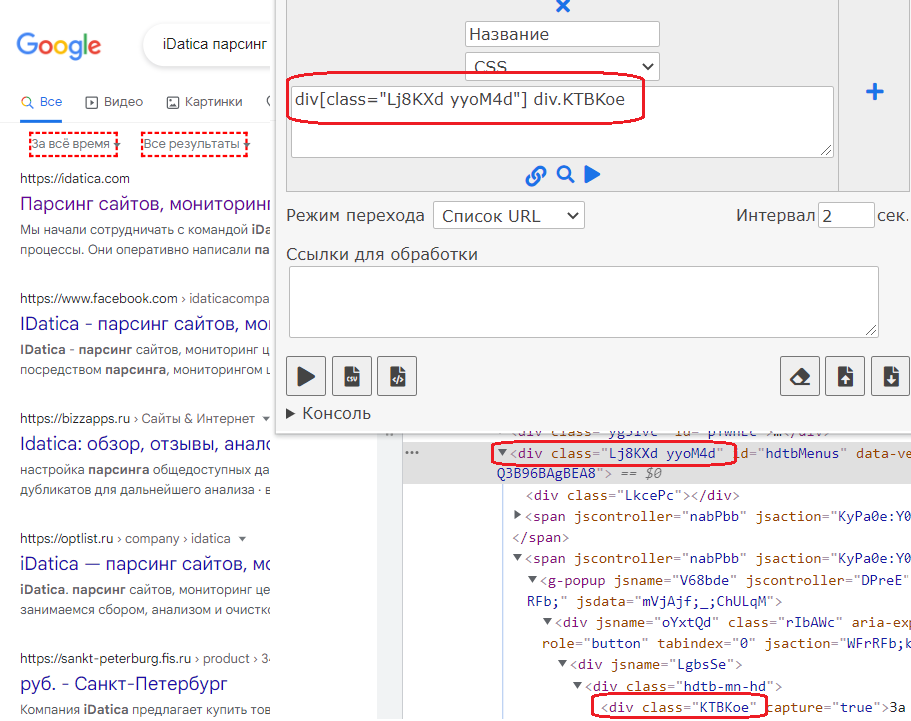
div[class="Lj8KXd yyoM4d"] div.KTBKoeCSS не позволяет найти родителя, тк поиск идет сверху вниз.
Возможности Xpath и CSS гораздо шире, но рассмотренные примеры хорошая база, каторая позволит решать большинство задач. Вы всегда можете поискать готовый пресет в нашем каталоге или если ваши задачи более масштабны, то обратиться за парсингом данных к нашим специалистам.





